
Click to Try The Demo
01
Research & Discovery
ISS Connect is a conversational AI assistant built for international students at the University of Washington.
It helps them navigate U.S. immigration regulations — F-1/J-1 visa compliance, OPT/CPT work authorization, SEVIS records, and international travel — through natural, accessible language, available 24 hours a day.
Powered by the ChatGPT API and grounded in official UW ISS and USCIS.gov sources, the assistant bridges the gap between overwhelmed students and overstretched advising staff — reducing anxiety and preventing legal missteps.
8,000+
UW international students
24 / 7
Instant availability
5
Ethical design principles
My role on this project was closest to a Product Designer:
I defined the problem space through research, shaped the solution through design decisions, and owned the ethical framework that governs the system's behavior.
02
Problem Statement


"I just want to know if I can travel while on OPT... but there are so many open tabs and no one can give me a straight answer."
— Student storyboard, the moment ISS Connect was designed to intercept
User Pain Points
International students at UW face a structural information gap.
Immigration rules are high-stakes, highly situational, and written in legal language — yet ISS advisor appointments take 3–5 business days, and government websites are dense and hard to navigate quickly.
In the absence of reliable real-time help, students default to peer advice and Reddit. This is not just inconvenient — a misunderstood visa rule can result in status violation, deportation, or denial of re-entry.

The framing that drove every decision
Before designing anything, I had to answer one question: what role should this product play?
Not a lawyer. Not an advisor replacement. Not a knowledge base.
The role I settled on was a knowledgeable peer — someone who knows the rules, is honest about limits, and always knows when to say 'go ask the advisor.' Every decision in this project flows from that definition.
03
Research & Problem Understanding
Sources
UW ISS Website — primary policy and procedure documentation
USCIS.gov — federal immigration law and regulations
NAFSA International Student Advising Guidelines — industry standards
Key Findings
Two compounding problems emerged.
the subject matter is genuinely complex
Visa rules are situational, overlapping, and frequently updated. 'Can I travel?' has different answers depending on visa type, OPT status, and whether the EAD card has arrived.
existing help infrastructure is structurally misaligned with the pace of student decision-making
Students need answers in hours, not days. When the official channel is unavailable, they do not wait — they find an unofficial one.
Design Thinking
Why research shaped the ethics, not just the features
Understanding the real-world consequences of wrong answers in this domain raised the bar for what 'helpful' means.
A helpful answer is not just one that addresses the question — it is reliably accurate, calibrated in its confidence, and honest about its limits. This recognition became the foundation of the ethical framework I built alongside the product design.
04
User Persona
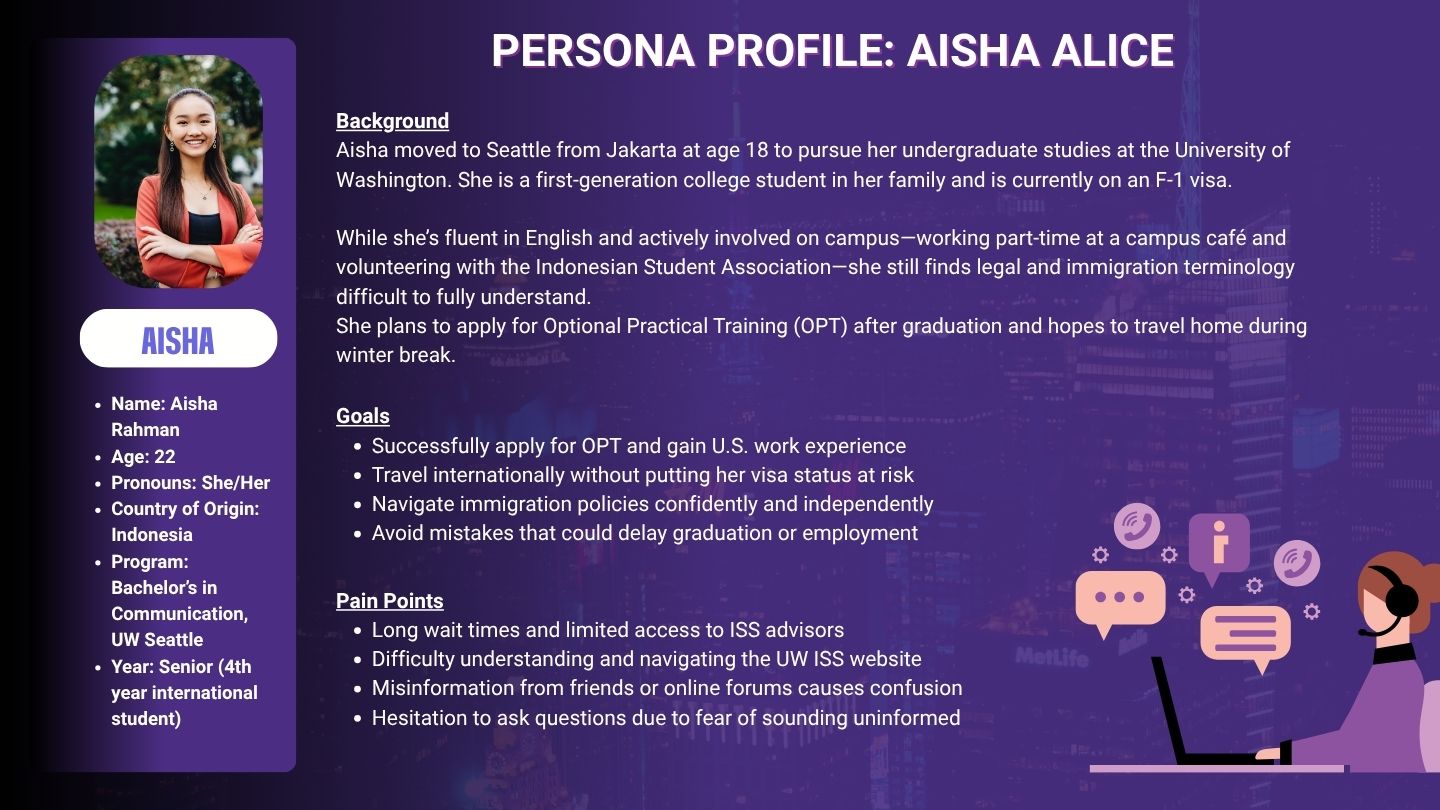
Design Thinking
Building empathy means modeling the emotional state, not just the demographic
Aisha represents a specific emotional state: high-stakes anxiety paired with self-consciousness about asking for help. This dual vulnerability — legal risk and the social risk of appearing uninformed — shaped the entire tone of ISS Connect. Non-judgmental, jargon-free, always closing with a clear next step. Designing for her emotional state was not a soft concern alongside the functional requirements. It was a functional requirement.
05
Design Challenges & Trade-offs
The hardest part of building this kind of product is not the technology itself. It is the design decisions behind it. These products come with a lot of built-in tensions, and there is no single right answer—only trade-offs. We broke our challenges down into four areas:

That means the job is not just about plugging ChatGPT into the product and wrapping it in a nice interface. We have to make thoughtful decisions across all of these layers.
Designing an AI assistant for legally sensitive information surfaced five fundamental tensions. None of them have clean resolutions. What follows is an account of how I identified each tension, what I considered, and what I decided — and why.
1
Helpful vs. safe — where to draw the line
The fundamental tension is that users come because they need answers, but in this domain, giving a confident wrong answer is more dangerous than giving no answer. AI systems naturally incline toward responses that feel complete and authoritative. In a legal context, that inclination is a liability.
The mistake to avoid was drawing a single universal line. The right threshold varies by the irreversibility of the consequence if the answer is wrong. 'How long does OPT processing take?' — getting this wrong costs inconvenience. 'Can I leave the country right now?' — getting this wrong could mean denied re-entry.
The approach I settled on: consequence-based risk tiering. Low-risk questions get direct answers. Medium-risk questions get answers with source citations and a note to verify before acting. High-risk questions get directional guidance only, with a clear recommendation to confirm with an ISS advisor. The harder follow-on question — who maintains this tiering as policy changes? — I documented as an explicit operational responsibility in the system specification.
2
Users do not ask questions the way you expect
You can build a well-structured intent library and still fail if you have designed for how you think users should ask rather than how they actually do. Real users say: 'I have to go home next month but my stuff isn't sorted yet, what should I do?' — no visa terminology, no recognizable keywords, but a genuine urgent immigration question underneath.
The core trade-off: coverage vs. accuracy. A system designed to handle anything will give vague or incorrect answers in edge cases. A system designed to only handle what it can handle well will decline more — but what it does answer, it answers correctly. For this user group, I chose accuracy over coverage. The consequence of a wrong answer is too high.
When the system cannot confidently match intent, it asks one clarifying question — presented as a choice, not an open field. 'Are you asking about travel before OPT starts, or during OPT while waiting for your EAD?' is far more useful than 'Can you describe your situation in more detail?' The one-question limit was deliberate: a multi-step clarification flow feels like an interrogation to an already-anxious user.
3
Trust calibration, not just trust building
Getting users to trust the product is relatively straightforward — friendly tone, official citations, clean design. The harder problem is calibrating that trust: ensuring users trust the AI exactly as much as its actual capabilities warrant, no more. Over-trust is the more dangerous failure mode. A user who treats the AI's answer as definitive without checking sources is exposed to real harm.
The approach: embed trust calibration into the language of every response, not as a disclaimer layer. Concretely — never say 'you need to' (say 'according to UW ISS policy, students are generally required to'); never state policy as fact without attribution; use hedge language proportional to actual uncertainty; always name the source so the user can verify independently.
The trade-off with fluency: heavily hedged language makes responses feel less natural. I resolved this by reserving strong hedge language for genuinely high-stakes situations, not applying it uniformly. Used selectively, it signals real uncertainty rather than becoming background noise that users learn to ignore.
4
Designing for users in an anxious state
Most product design implicitly assumes a user who is calm, has time, and will read what you put in front of them. ISS Connect's users are often none of these things. They are stressed, under time pressure, and dealing with a topic where they feel cognitively outmatched. Standard UX assumptions break down.
The key implication: information hierarchy has to do real work. The first sentence of every response must stand alone as a useful answer — a user who reads only the first sentence should be better informed than before they asked. The rest — source link, nuance, caveats, booking suggestion — is for users who have the cognitive space to continue.
This inverted pyramid creates a trade-off with accuracy: the first sentence must be simple, so it cannot capture every exception. My resolution: the first sentence states the general rule, the second immediately flags the most common exception. The user is never misled by the simplification — it is always visibly qualified. The deeper limitation: you cannot reliably test for this in a standard usability session. You cannot recreate genuine anxiety in a research environment. The persona and storyboard were proxies, not the real thing.
5
The system's knowledge will become outdated
Immigration policy changes. Processing times fluctuate. A response accurate in March may be wrong in September. For a static FAQ, this is a manageable content maintenance problem. For a conversational AI that users interact with as if it has current knowledge, it is a trust and safety problem. The specific danger: the system will give outdated information with the same apparent confidence as current information.
Two parallel strategies. First: for high-volatility information — OPT processing times, fee amounts, specific deadlines — the response never states the number directly. It links to the authoritative source where the current number lives, with a note that this figure changes regularly. The AI provides context and interpretation; the live source provides the fact.
Second: I separated the content layer from the conversation layer. The prompt does not hardcode time-sensitive facts — it references external content sources. When those sources update, the system's responses update with them. But the most important decision: acknowledging that neither strategy removes the need for a human to own content maintenance. No architecture solves this. I documented it as an explicit operational requirement: someone must review the content layer against current policy on a defined schedule.
The three questions I asked before every trade-off
Across all five challenges, I found myself returning to the same three questions before making a decision.
Queation
What to Consider
What is the asymmetry of the error?
If this decision is wrong, who bears the cost — user or product? Is it reversible? Decisions where a wrong call causes irreversible harm to the user should default to the more conservative option.
Who maintains this decision over time?
A design choice that requires ongoing human attention to remain valid is only as good as the operational structure behind it. Make the dependency explicit, not assumed.
What does this look like for the most vulnerable user?
Not the average user — the most anxious, least domain-familiar, most likely to take the AI's output at face value. If that user would be misled, the decision is wrong regardless of how it performs for everyone else.
06
Design Decision
Decision 1 — The product's role
The single most important decision was defining what ISS Connect is and is not.
Not a lawyer, not an advisor replacement, not a knowledge base.
A knowledgeable peer: knows the rules, is honest about limits, always knows when to send you to a human.
This role definition had direct implications for tone, fallback logic, intent library scope, and the ethical framework.
Decision 2 — Dawg: mascot over digital human
Three options evaluated: photorealistic digital human, plain chat interface, branded mascot.
The digital human scored high on warmth but risked users mistaking it for a real person — a serious trust miscalibration. A plain interface avoided this but sacrificed the emotional connection that makes students comfortable asking embarrassing questions.
Dawg — a cartoon husky in UW school colors — is clearly non-human, which makes the AI nature of the interaction transparent. It borrows institutional credibility from the UW brand. And it provides emotional warmth without the ethical risks of a photorealistic avatar. The transparency was not just ethical hygiene — it directly supports trust calibration.

Design sketches & Ideas

Decision 3 — Intent mapping before prompt writing
Before writing a single line of system prompt, I built a structured utterance-intent library: mapping real student questions to the underlying informational need. Prompt engineering, for a product designed for a specific user group, is a form of interaction design. The precision with which you define the system's identity, scope, tone, and escalation logic determines the quality of every response. A vague prompt produces a vague product.

Decision 4 — The fallback as a trust mechanism
The fallback response — 'This situation is complex; I recommend scheduling an appointment with an ISS advisor' — was not a failure state. It was a deliberate trust-building mechanism.
A system that claims to answer everything erodes trust the first time it gets something wrong. A system honest about what it cannot handle builds a different kind of trust: users learn that when it does give an answer, they can rely on it.
Decision 5 — Persistent context over repeated disclosure
Every time a student opens a conversational AI assistant, they face the same invisible friction: before they can ask their actual question, they have to re-establish who they are. What visa they are on, where they are in their program, whether their OPT has been approved. For a student already dealing with anxiety and time pressure, that setup cost is real. And it creates a second, more dangerous problem: when users describe their own situation in natural language, they often get it slightly wrong. The AI responds to their description rather than their actual situation. The answer sounds personalized but is built on an unstable foundation.
ISS Connect addresses this with a persistent user profile. On first use, students upload their core identity documents — their I-20, visa page, and EAD card if they have one. The system reads these and extracts a structured profile: visa type, program end date, OPT or CPT authorization status, and current validity window. This profile is stored to the student account and automatically injected into the context of every subsequent conversation.
From that point, Aisha does not introduce herself to Dawg. She just asks. 'Can I travel right now?' lands in a system that already knows she is an F-1 student, OPT pending, EAD not yet received. The answer it generates is not the general answer to that question — it is the answer to that question for her, specifically. And the escalation logic becomes more precise: 'Given that your EAD has not arrived and you are planning to travel in three weeks, I would strongly recommend confirming with an ISS advisor before you book flights.' That sentence is only possible because the system knows her situation.
The tensions this feature introduced
Storing immigration status information sits directly in tension with the privacy principles we had already committed to. The resolution required two specific decisions. First, the system does not store the documents themselves — only the structured fields extracted from them. Source files are parsed and then discarded. This minimizes what the system holds while preserving what it needs to function.
Second, AI document parsing is not perfectly reliable. An I-20 is a standardized form, but variations in scan quality and formatting mean the extracted information can be wrong. If the system silently writes an incorrect program end date or misreads an OPT authorization, every response built on that profile is compromised — and the student may not realize it until something goes wrong.
The design response was a mandatory confirmation step. After parsing, the system surfaces what it understood in plain language: 'Here is what I recorded — F-1 visa, program end date August 2025, OPT not yet applied for. Does this look right?' The student confirms or corrects before the profile becomes active. This adds a small amount of friction at setup, but it prevents a much worse failure mode downstream: a student acting on advice that was personalized to the wrong version of their situation.
07
User Junrney Map

Mapping Aisha's full journey revealed that the most important design opportunity was not answer quality, but the entry point: catching her at the moment of confusion, before she defaults to Reddit.
08
The Solution

System architecture
Frontend
Backend
Content Layer
Safety Layer
Userprofile
Frontend — embedded chat widget. Familiar conversational interface, zero learning curve.
Backend — ChatGPT API with a carefully engineered system prompt defining identity, scope, tone, and escalation thresholds.
Content layer — pre-mapped utterance-intent library. ESL-optimized language guidelines applied at prompt level.
Safety layer — consequence-based risk tiering, fallback logic, source citation requirements, explicit 'not legal advice' framing.
User profile layer — structured immigration status extracted from uploaded documents (I-20, visa page, EAD), stored per account, injected into every conversation. The layer that makes responses specific rather than generic.
Sample conversation

09
Ethical AI Framework
The ethical framework was not built after the product was designed. It was built in parallel, because the design decisions and the ethical decisions were often the same decision.
#
Principle
Descricption
01
Accuracy & Compliance
Only cites UW ISS and official government sources. Never speculates or presents information without attribution.
02
Privacy & Confidentiality
Never stores personal data. The UI never prompts users for visa numbers or personal details.
03
Clarity & Actionability
Every response ends with a clear next step. Information without a path forward is anxiety, not help.
04
Respect & Inclusion
Non-judgmental tone regardless of how basic the question. ESL-optimized language throughout.
05
Not Legal Advice
Dawg is transparent about what it is and is not. Stated in the interface and embedded in every complex response.
Design Thinking
Ethics as a design constraint, not a compliance checklist
Every ethical principle had a direct design implication. 'Privacy' meant no data retention, but it also meant the UI never asked for names or visa numbers. 'Not legal advice' meant the fallback message was crafted with a specific tone — helpful but clearly bounded. The most important ethical decision was the mascot choice: by making Dawg clearly non-human, we reduced the risk of users over-trusting the AI with decisions that require human judgment.
10
Results & Deliverables
ISS Connect AI chatbot prototype
with full conversation flow demonstration ISS Connect
Dawg mascot brand identity
— from sketch concepts to finalized digital character Dawg
Research documentation
target audience analysis, pain point synthesis, information architecture
Prompt design specification
utterance-intent library, risk tiering framework, fallback logic Prompt
Customer journey map
Aisha Rahman's complete four-stage experience pathway
Ethical AI framework
operational principles governing accuracy, privacy, tone, and legal boundaries
Scalability
ISS Connect's architecture is institution-agnostic. The ChatGPT backend supports multilingual prompts; the content layer can be reconfigured per campus; the ethical and UX framework transfers directly to any institution serving international students.
11
Reflection & Learnings
What this project taught me about AI product design
The most useful reframe: prompt engineering is interaction design. The system prompt is not a technical artifact beneath the design — it is the design, in the sense that it determines every interaction the user has with the product. Learning to think of it that way changed how I approached every decision.
I also learned that designing for trust requires designing for the failure modes first. The fallback logic, the trust calibration in the language, the risk tiering — these were more important to the product's integrity than any of the positive-path features.
What I would do differently
I would conduct usability testing with real UW international students before finalizing the response language. The persona work gave me a strong model of the user's emotional state — but it is still a model. Real users in research sessions would have surfaced language assumptions I made unconsciously.
I would also invest more time in the operational specification: the content review schedule, the policy monitoring responsibility, the process for updating the intent library when regulations change. The design is only as durable as the operational structure behind it.
The best AI products are not the ones that answer everything — they are the ones that know exactly what they should and should not say, and make that boundary feel like a feature, not a limitation.
